硬件概况
目前我司用于大数据分析的服务器共20台,均为64位系统,64G内存,其中名称节点4台,磁盘空间100TB,数据节点16台磁盘空间560TB。
软件环境
目前我司用于大数据分析的服务器共20台,均为64位系统,64G内存,其中名称节点4台,磁盘空间100TB,数据节点16台磁盘空间560TB。
我们目前所使用的当前非常流行的的Hadoop集群,版本hadoop-2.6.0-cdh5.4.4,此是Apache基金会所开发的免费分布式系统基础架构,可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。其主要功能分HDFS和MapReduce两部分。
1、Hadoop集群HDFS存储架构
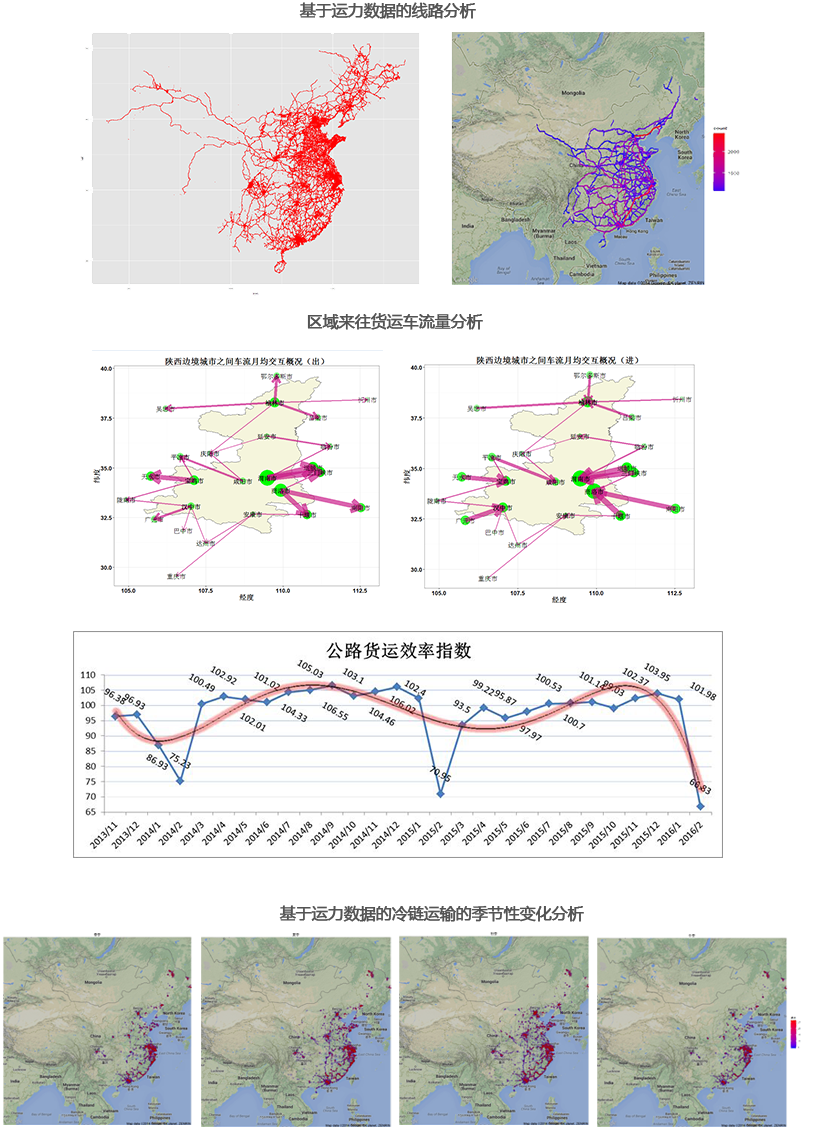
HSDS的架构如上图所示,总体上采用了Master/Slave的架构,主要有以下4个部分组成:
■ Client
■NameNode
整个HDFS集群只有一个NameNode,它存储整个集群文件分别的元数据信息。这些信息以fsimage和editlog两个文件存储在本地磁盘,Client通过这些元数据信息可以找到相应的文件。此外,NameNode还负责监控DataNode的健康情况,一旦发现DataNode异常,就将其踢出,并拷贝其上数据至其它DataNode。
■Secondary NameNode
Secondary NameNode负责定期合并NameNode的fsimage和editlog。这里特别注意,它不是NameNode的热备,所以NameNode依然是Single Point of Failure。它存在的主要目的是为了分担一部分NameNode的工作。
■DataNode
DataNode负责数据的实际存储。当一个文件上传至HDFS集群时,它以Block为基本单位分布在各个DataNode中,同时,为了保证数据的可靠性,每个Block会同时写入多个DataNode中。
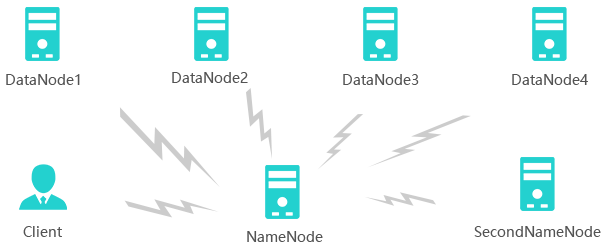
2、Hadoop任务MapReduce架构设计
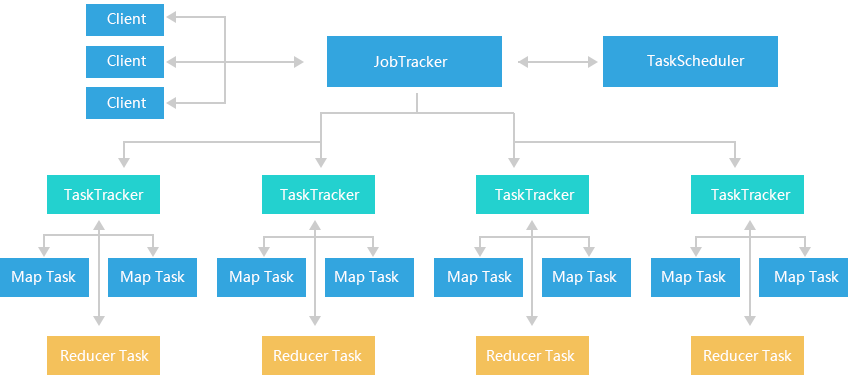
3、数据分析过程
数据分析的主要过程如下图所示,首先详细分析任务需求,根据具体需求收集选择相关数据,并针对数据中的一些异常值进行过滤或处理。由于一般数据所需的数据量非常大,所以需要设计Hadoop的MapReduce程序对数据进行加工处理,将加工处理的结果再利用R语言进行各种类型的分析,如:数据概览、探索性分析、关联分析、聚类、分类等,并评估相关数据结果,如果结果未能达到预期需要,则需分析问题可能原因,并重新收集整理、处理、分析数据,直到达到预期期望,最后整理相关数据,绘制数据说明图表,并形成数据分析报告。
易流数据分析主要方向
目前我们公司数据分析工作主要集中在以下四个方面:
基础数据
基础数据是以车辆运行轨迹数据与车辆所属公司、用户等基础信息为基础所进行的数据分析,主要有:行停分段、线路解析、运输类型、停车区域、运行时段、车辆综合信息等。
微信研报
微信研报主要是根据现有数据,对一些已知可能的现象进行验证和根据一些数据现象得出某些结果,如双十一、车距与车次、车辆停车点分析等。
配合其他部门及同事
根据某些团队和同事需要,组织并分析数据,并对数据结果进行可视化展示。如:运维中心停车点分布、广东办申通车辆运行效率与行业对比、宅急送运单及运行效率等。
公路货运效率指数
公路货运效率指数是中物联提出以数据指数值反应中国公路货车辆利用率的概念。指数值从2013-11月份开始,2015-1月开始测试,每月发布一期。
举例说明
现以公路货运效率指数实现过程为例说明。 需求:中物联提出公路货运效率指数的概念,以了解每月的全国的公路货运效率情况。 需求分析 其中关键词有:每月、全国的、公路货运、效率、指数。
问题:数据时间段是?如何以易流的少量车反应全国的运行情况?公路货运车都包括什么?什么是车辆运行效率?指数是什么,基准是什么,如何表现?都需要收集哪些数据?
思路整理:以中国公路货运市场中的各车型的比例为基础,对易流车辆按车型进行同比例取样,按照月份尽可能取最多的车,并对2013-11月份以来的车辆运行轨迹数据进行分析得到以里程、时长为基础加权计算得到月均运行效率值,再以2014年全年的年月均效率值为指数基数100,每月相对于此基数的变化情况则定位当月的运行效率指数。
收集数据 根据上面的设计思路,所需要数据主要有:2013-11月以后的所有车辆运行轨迹数据,易流所有车的车辆类型数据,全国货运车辆车型比例。
预处理 ■车型比例:结合全国与我们的车辆的车型情况选择车型比例如下。 ■轨迹数据:过滤或处理车辆运行时的经纬度、里程跳跃、经常掉线的车。 ■车辆筛选:每月按各分类比例随机选车作为样本车。
| 车型 | 车辆分类 | 比例(%) |
|---|---|---|
| 冷藏运输半挂车 | 挂车 | 0.35 |
| 厢式运输车半挂车 | ||
| 平板半挂车 | ||
| 集装箱半挂车 | ||
| 高栏半挂车 | ||
| 冷藏厢车 | 吨车 | 0.6 |
| 冷藏吨车 | ||
| 厢式吨车 | ||
| 高栏吨车 | ||
| 铁笼车 | ||
| 保温车 | ||
| 散装水泥运输半挂车 | 专车 | 0.05 |
| 车辆运输半挂车 | ||
| 油罐半挂车 | ||
| 自卸车 |
Hadoop计算
■计算车辆月运行时长、里程。
■计算各类型月均运行时长、里程。
■计算各月月均运行时长、里程。
■根据指数计算公式计算各月货运效率指数。
R可视化处理
使用Hadoop分析所得的各月指数数据,绘制曲线图,观察各月数据变化,如果有异常则进行异常分析,并优化算法程序。
结果评估及优化改进
如对样本数的改进:开始采用固定总样本数与固定车型样本车数比的算法,但由于我们公司车辆数是不断增加的,因此不论如何取都无法最大程度选择我们公司可用的车。而样本车数的多少关系到计算结果的可信度,所以在总结分析之后,将每月的车辆总样本数设定为按照既定车型比例关系下的最大满足度车辆数,一个变动的数。
数据分析报告
整理分析过程、设计思路及数据结果、图表等信息,形成分析报告文档。